XHTML 1.0 Strict で制作したページをW3C Markup Validation Service でチェック。
結果は、
This document was successfully checked as XHTML 1.0 Strict!
Passed, 1 warning(s)
むむ? 何が「warning」なのかな? と思いながら読み進めると・・
Byte-Order Mark found in UTF-8 File.
The Unicode Byte-Order Mark (BOM) in UTF-8 encoded files is known to cause problems for some text editors and older browsers. You may want to consider avoiding its use until it is better supported.
Byte-Order Mark???? ということで調べてみると。
BOMとは、UnicodeのUTF-16など16ビット幅のエンコーディング方式において、エンディアンを指定するためにファイルの先頭に記入される16ビットの値。
(中略)
BOMはエンディアンの判別だけでなく、文書がUnicodeで記述されているかどうかを判別するために用いられることもある。このため、エンディアンが関係ないUTF-8などの文書でも先頭にBOMがついている場合がある。
ふむ。先頭に不要な値がついているのですね。ということで、このBOMを削除する方法を検索。「Binary Editor BZ」で削除できるようなので、窓の杜からさっそくDLしてインストール。問題のファイルをこのソフトで開いてみると。
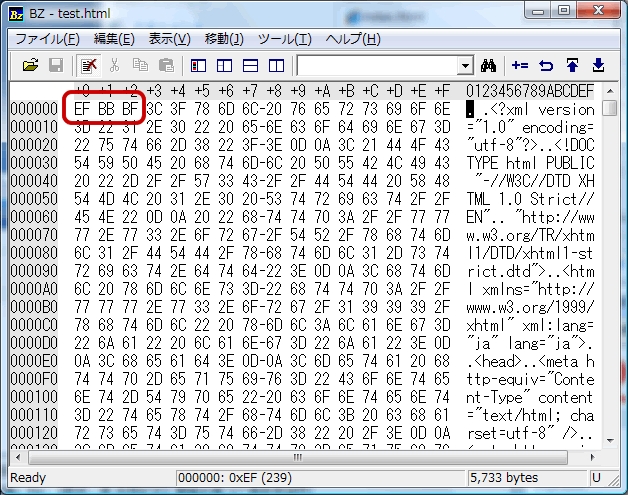
どうやら先頭の「EF BB BF」が Byte-Order Mark ・・らしい。
さっそく削除して、再度 Validate。ようやくPASS することができました。
めでたし、めでたし。なのですが、ここで新たな疑問が。
EF BB BF って何?